AI Agent Workbench
Advanced Operation Settings
Learn how to fine-tune your agent’s operations with advanced configuration options
Customizing Operation Behavior
Each operation in your agent can be fine-tuned with advanced settings to control exactly how it functions. These settings help you create more reliable, efficient, and secure agents by controlling data flow and execution behavior.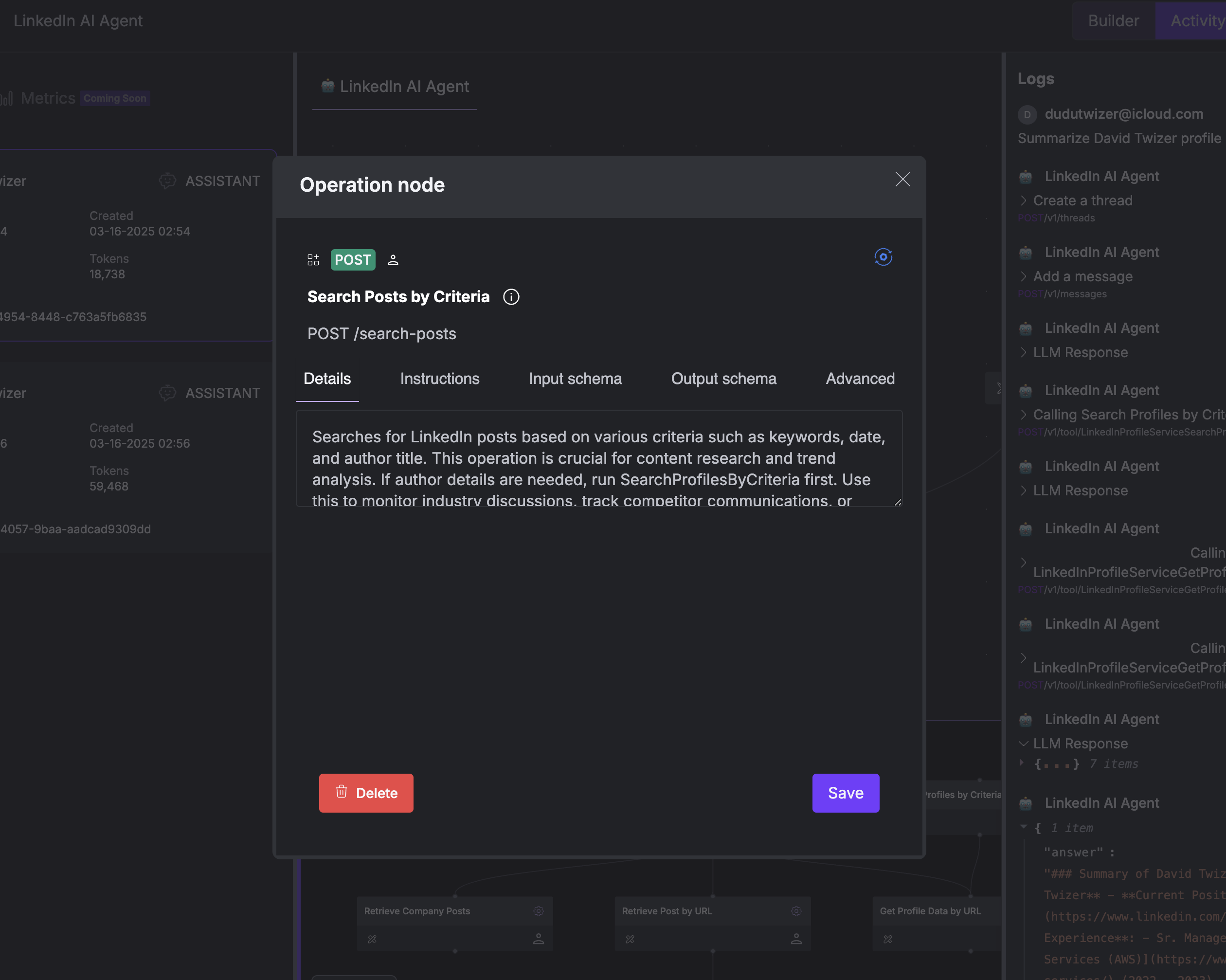
Operation Configuration Tabs
When you select an operation in the builder interface, you’ll see several configuration tabs that control different aspects of the operation’s behavior:The Details tab shows the original, generated function calling description that defines the operation’s purpose and behavior. This serves as a reference for the operation’s intended use.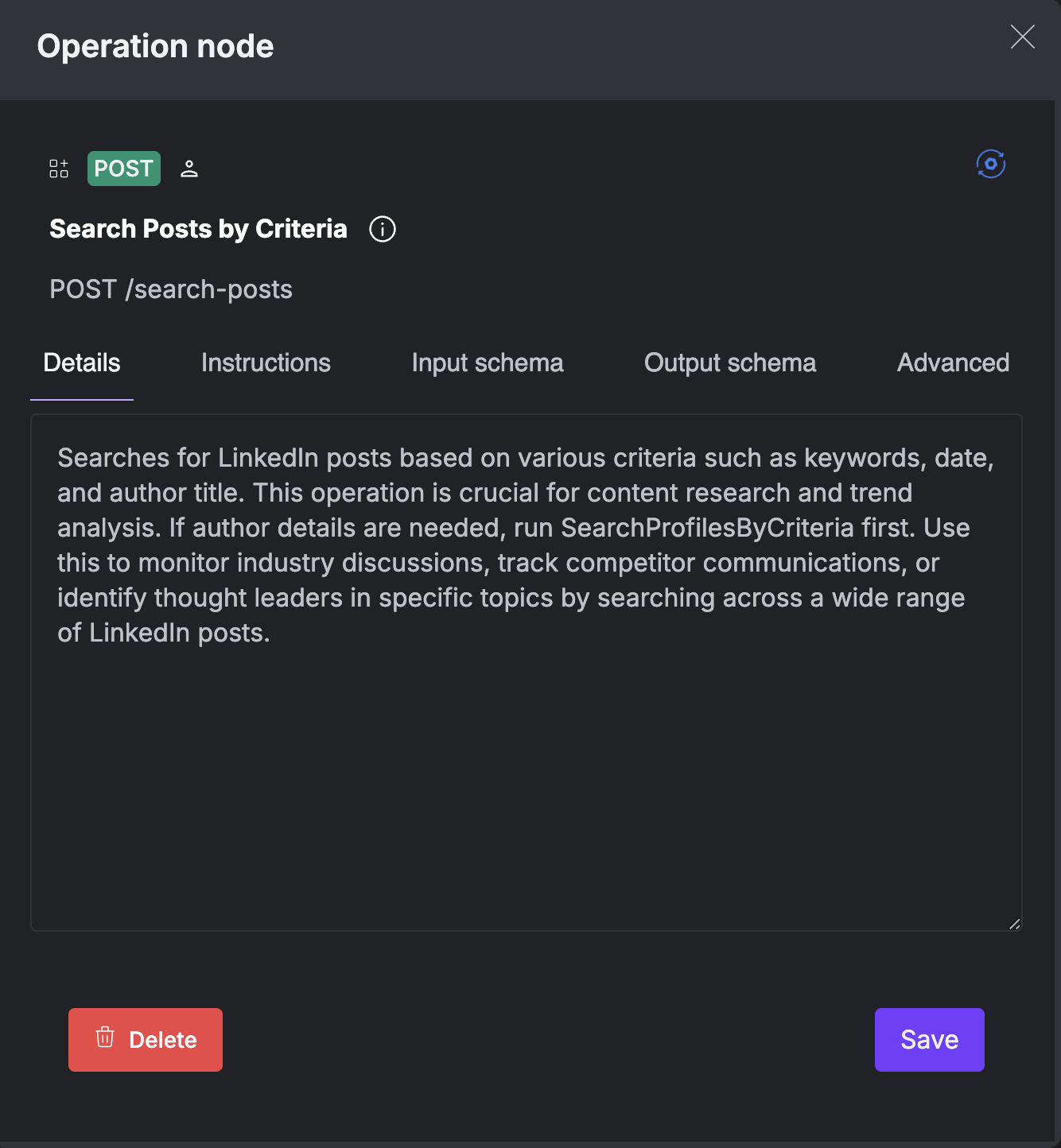 This information is especially useful when you’re working with multiple similar operations and need to understand the exact purpose of each one.
This information is especially useful when you’re working with multiple similar operations and need to understand the exact purpose of each one.
Operation Execution Settings
Controlling Operation Repetition
Controlling Operation Repetition
The blue rotating icon in the operation settings allows you to configure how many times an operation can be executed: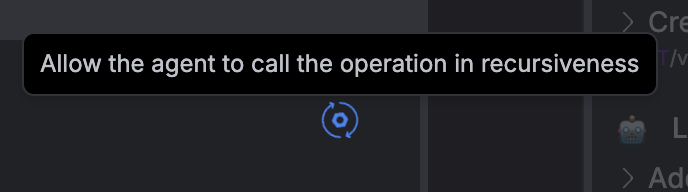 You can set operations to:
You can set operations to:
- Execute once: The operation can only be used a single time in a given session (useful for initialization operations)
- Execute infinitely: The operation can be used repeatedly as needed (default for most operations)
- Have rate limits or usage quotas
- Should only be performed once per session for logical reasons
- Need to be used repeatedly to gather comprehensive data
Practical Examples
Example: Sanitizing LinkedIn Profile Data
Example: Sanitizing LinkedIn Profile Data
When building a LinkedIn researcher agent, you might want to remove personal contact information before passing profile data to the AI:
- Select your “Get Profile Data” operation
- Click the “Output Schema” tab
- Expand the response schema tree
- Uncheck fields like
emailAddress,phoneNumbers, and other personal fields - Leave professional information like
title,company, andskillschecked - Save your changes
Example: Optimizing for Large Datasets
Example: Optimizing for Large Datasets
If your agent needs to work with a large dataset of company posts:
- Select your “Search Posts” operation
- Click the “Advanced” tab
- Enable “Allow in-context filtering”
- Configure which fields should be available for filtering
- Save your changes
Best Practices
- Start with minimal output: Only include fields the AI actually needs to complete its task
- Use input defaults wisely: Hard-code parameters that should remain constant, but allow flexibility for case-specific values
- Provide clear instructions: Help the AI understand exactly when and how to use each operation
- Test thoroughly: After configuring advanced settings, test your agent with various inputs to ensure it behaves as expected
- Monitor token usage: Use the Activity view to track how your configuration changes impact token consumption